Was ist Maschinelles Lernen?
Wenn wir von intelligenten Algorithmen sprechen, trifft das keine Aussage über die verwendete Methode. KI ist also ein großes Feld. Innerhalb dieses Bereichs, bezeichnet Maschinelles Lernen (ML) ein Teilgebiet von Programmen, die selbständig lernen. Genauer gesagt: Diese Programme sind für bestimmte Aufgaben entwickelt worden und können diese selbstständig anhand von Beispielen lösen (frei nach Prof. Ulrike von Luxburg). Dabei sind folgende Aspekte wichtig für die Definition: Es geht bei diesen Anwendungen immer um spezielle Aufgaben, sei es Bilderkennung oder Übersetzung von Texten – wie auch schon im vorhergehenden Kapitel kurz aufgegriffen und als schwache KI bezeichnet. Außerdem besteht die prinzipielle Herangehensweise darin, dass zunächst Beispiele genutzt werden, damit der Algorithmus daraus selbstständig lernen kann. Was das genau bedeutet, soll in den kommenden Kapiteln detaillierter erklärt werden.
Innerhalb des Maschinellen Lernens gibt es noch das sogenannte Deep Learning, das besonders große neuronale Netze nutzt, um sehr komplexe Muster aus riesigen Datenmengen zu erkennen, was z.B. in der Spracherkennung verwendet wird. Dazu später mehr.
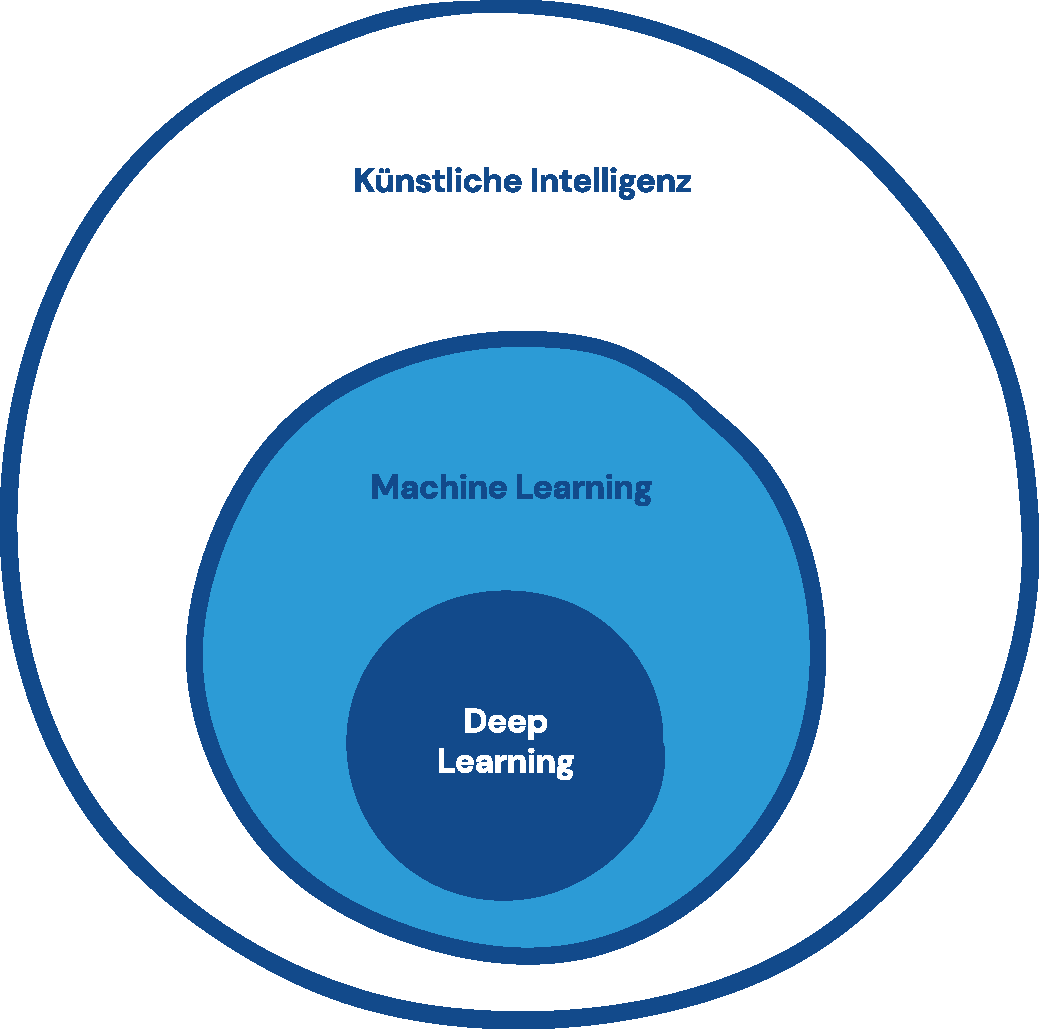
Zur Künstlichen Intelligenz gehört das Maschinelle Lernen. Deep Learning ist davon wiederum ein Teilgebiet.
CC BY SA 4.0 Luise Wüstling und KI Makerspace
Wenn von KI-gestützten Systemen gesprochen wird, ist also nicht klar, worum es sich genau handelt. Hier muss jedes Tool, das vorgibt KI zu nutzen, mit kritischem Blick geprüft werden.
Wofür braucht man ML?
Algorithmen, die Maschinelles Lernen (ML) benutzen, zielen darauf ab, Muster in Daten zu erkennen und auf dieser Basis Entscheidungen oder Vorhersagen zu treffen. Das ist insbesondere bei großen Datenmengen oder komplexen Fragestellungen relevant. Im Gegensatz dazu brauchen regelbasierte Methoden genaue Anleitungen, was mit der Eingabe zu tun ist. Aber dieser Ansatz führt nicht bei allen Fragestellungen zu passenden Antworten. Das folgende Beispiel soll dies verdeutlichen.
Stellen wir uns vor, wir brauchen eine Anwendung, um Tierbilder zu klassifizieren, beispielsweise um eine Katze auf einer Vielzahl von Bildern zu erkennen. Wir Menschen sind gut im Erkennen von Mustern, jedoch wären es vielleicht zu viele Bilder, sodass es sehr mühsam wäre, alle durch Menschen prüfen zu lassen. Also soll ein Programm das für uns tun. Als Eingangsdaten haben wir also Bilder (Input) und der Algorithmus entscheidet dann darüber, ob es eine Katze ist oder nicht und gibt eine Antwort Ja
/Nein
zurück (Output). Nun müssen wir also überlegen, wie der Algorithmus zu einer Entscheidung kommen kann.
Zunächst stellen wir uns die Frage, wie wir Katzen definieren könnten. Wir bilden Kategorien, was bei einer Katze vorkommen muss oder optional vorhanden sein kann. Beispielsweise haben Katzen in der Regel spitze Ohren, Fell, vier Beine, grünliche Augen, Schnurrhaare etc. Doch was ist mit einem Bild, bei dem die Katze unter einer Decke versteckt ist und ihre Ohren somit nicht sichtbar sind? Oder was ist mit einem Hund, der auch spitze Ohren, Fell und vier Beine hat? Nutzt man regelbasierte Systeme, wäre es nur schwerlich möglich hier gute und zuverlässige Aussagen zu treffen. Modelle, die ML nutzen, können hingegen aus einer Vielzahl an Katzenbildern, mit der man die Systeme zuvor gefüttert hat, Muster erkennen, ohne dass diese zuvor definiert wurden. Mittlerweile sind solche Programme in vielen Anwendungsfeldern auch besser als Menschen. Was für maschinelles Lernen notwendig ist und wie das genau funktioniert, soll in den folgenden Kapiteln erklärt werden.
Die Verwendung von ML ist immer dann interessant, wenn es für ein Problem oder eine Fragestellung keine analytisch berechenbare Lösung gibt oder wenn die Berechnung einer Lösung zu viel Rechenkapazität benötigen würde.
