Anwendung: Klassifikation & Regression
Klassifikation und Regression
Zwei gängige Problemstellungen im maschinellen Lernen sind Regression und Klassifikation. Bei der Regression will man kontinuierliche Werte vorhersagen, beispielsweise Schätzung der Temperatur in Abhängigkeit von Wetterparametern, Hauspreise in der Zukunft basierend auf Fläche und Lage des Hauses oder wie beeinflusst die Anzahl der Stunden, die ein Schüler lernt, die Prüfungsergebnisse?
Algorithmen für Regression:
- Lineare oder logistische Regression
- Entscheidungsbäume
- Random Forest
- Support Vector Machines (SVM)
- Neuronale Netze
Die Klassifikation führt zu diskreten Zuordnungen, wie z.B. anhand bestimmter Körperwerte zu beurteilen, ob Person XY krank oder gesund ist. Weitere Beispiele dafür sind die Beurteilung einer Mail als Spam/Nicht-Spam, ein Bild als Hund oder Katze oder die Generierung von Empfehlungen.
Algorithmen für Klassifikation:
- Logistische Regression
- Entscheidungsbäume mit diskreten Werten
- Naive Bayes classifier
- k-Nearest Neighbors
- Support Vector Machines (SVM)
- Neuronale Netze
Die Unterschiede zwischen Regression und Klassifikation sind im Folgenden aufgelistet.
|
Merkmal |
Regression |
Klassifikation |
|
Zielvariable |
Kontinuierlich (numerisch) |
Diskret (kategorisch) |
|
Ziel |
Vorhersage eines Werts |
Zuordnung zu einer Klasse |
|
Beispielanwendungen |
Vorhersage des Hauspreises |
Erkennen, ob ein Bild eine Katze zeigt |
Beide Methoden sind essenziell im maschinellen Lernen und je nach genauer Zielsetzung werden andere Modelle angewendet.
Mustererkennung
Im Bereich der Klassifikation spielt die Bilderkennung eine große Rolle im maschinellen Lernen. Es ist ein klassisches Beispiel dafür, dass regelbasierte Systeme zu keinem geeigneten Ergebnis führen. Haben wir eine Reihe von Bildern und wollen die Bilder herausfiltern, die Katzen zeigen, dann müssten wir in einem regelbasierten System definieren, woran eine Katze erkannt werden könnte. Hier könnte man spitze Ohren, Fell, vier Pfoten und Ähnliches nennen. Hier stoßen wir jedoch an eine Grenze, weil auch andere Tiere wie Hunde spitze Ohren haben können, vier Pfoten und Fell. Maschinelles Lernen ist also dafür geeignet Muster zu erkennen, die wir nicht mehr eindeutig definieren können. Bei selbst lernenden Systemen hat der Algorithmus sehr viele Katzenbilder gesehen und erkennt (im besten Fall) die relevanten Muster, um Katzen von Hunden unterscheiden zu können.
Wie ein solches selbst lernendes System trainiert wird, soll im nächsten Abschnitt erklärt werden.
Zahlenerkennung
Für die Post ist beispielsweise die Erkennung von Zahlen (ebenso wie die Buchstabenerkennung) auf handschriftlich beschrifteten Briefen wichtig, um ihre Prozesse effizient umsetzen zu können. Am Beispiel der Zahlenerkennung soll nun veranschaulicht werden, wie ein neuronales Netz trainiert wird. Dazu braucht es zunächst einen großen Datensatz mit sehr vielen Zahlen.

Sammlung an Zahlen von 0 bis 9. Ausschnitt aus dem MNIST Datensatz von Joseph Steppan, CC BY SA 4.0 via Wikimedia Commons [abgerufen: 04.09.2025]
Zu den Zahlenbildern wird stets ein Label hinzugefügt, welche Zahl dargestellt ist. Das Bild einer 2
wird mit dem Wort 2
verknüpft. Der Algorithmus hat die Zielvariabel also stets integriert. Für das Training wird jedes Pixel der Zahlenbilder (Graustufenwerte) als Eingabe für das neuronale Netz genutzt. Die Ausgabe ist die Wahrscheinlichkeit für jede Zahl zwischen 0 und 9.

Ablauf der Zahlenerkennung mit Input, Algorithmus und Output.
CC BY SA 4.0 KI-Makerspace Tübingen
Nun wird mit einer Vielzahl von verschiedenen Zweien trainiert und die Ausgabe wird mit dem bekannten Ergebnis überprüft und gegebenenfalls werden die Gewichtungen im neuronalen Netz angepasst bis das Ergebnis den Erwartungen entspricht und mit neuen, unbekannten Daten trainiert wird.
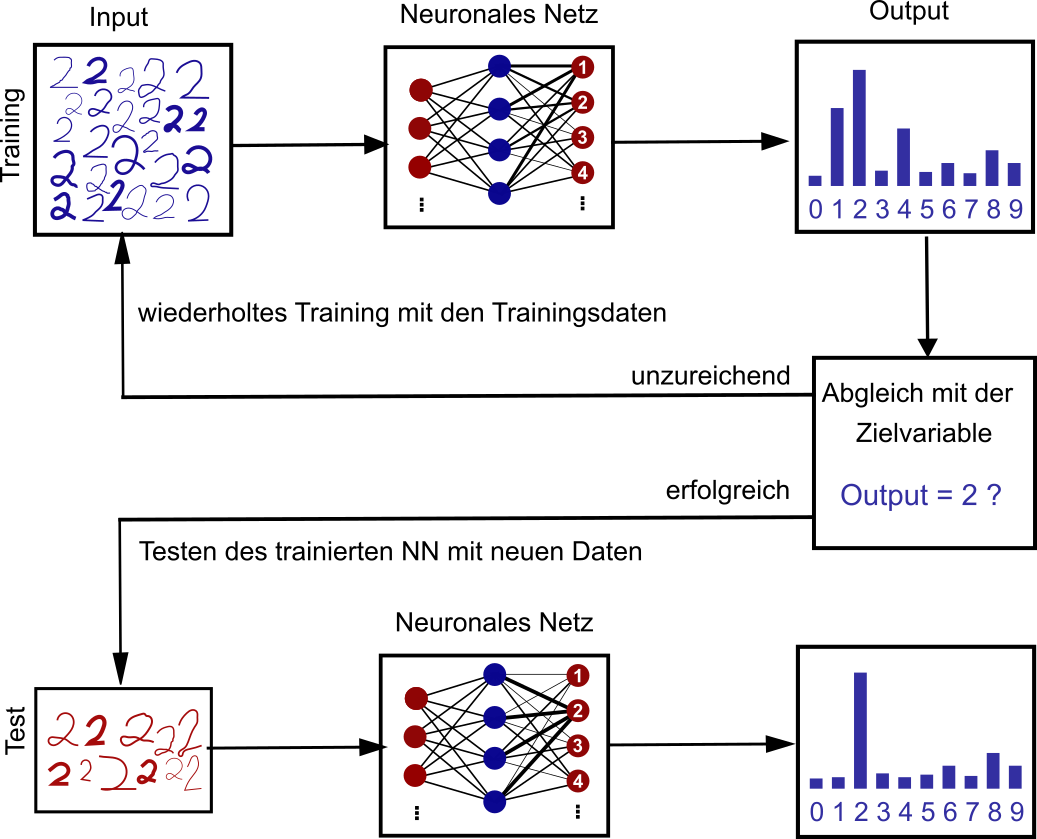
Ablauf der des Trainings und Testings der Zahlenerkennung.
CC BY SA 4.0 KI-Makerspace Tübingen
|
Um zu visualisieren, wie wichtig die Menge an Trainingsdaten für die Erkennung von Zahlen ist, kann folgende Seite genutzt werden: https://www.i-am.ai/neural-numbers.html Hier gibt es interaktive Flächen auf denen Zahlen geschrieben werden können. Dahinter stehen Neuronale Netze, die mit einer unterschiedlichen Menge an Zahlen trainiert wurde. Aufgabe:
Ziel: Mit diesen Aufgaben kann die Rolle von Trainingsdaten verdeutlicht werden. Einerseits brauchen wir genug Trainingsdaten, um präzise Antworten zu erhalten, andererseits wird auch offensichtlich, dass unterschiedliche Repräsentationen innerhalb der Trainingsdaten wichtig sind und unvollständig sein können (Aufgabe 4). Dieses Video von 3blue1brown erklärt anschaulich weitere Details zur Zahlenerkennung und ist auch schriftlich auf deren Website nachzulesen. |
Bilderkennung
Das Prinzip ist ähnlich, um Bilder zu erkennen. Trainiert wird das Neuronale Netz mit bekannten Bildern. Es wird ein großer Datensatz an bekannten Bildern genommen, bei denen man vorher weiß, was dargestellt wird. Weil natürlich die Anzahl an möglichen Objekten in Bildern weit größer ist als die Anzahl an Ziffern, sind die Neuronalen Netze weitaus fehleranfälliger bei der Identifizierung von Bildern.
Außerdem werden teilweise Muster erkannt, die mit dem dargestellten Objekt nur bedingt etwas zu tun haben. In einer Studie wurde untersucht, welcher Teil des Bildes für den Algorithmus ausschlaggebend für die Beschriftung ist. Ein Beispiel ist die Erkennung von einer bestimmten Fischart, der Schleie, die typischerweise anhand der Finger des Menschen erkannt werden, die diesen Fisch in die Kamera halten. Interessierte können das wissenschaftliche Paper auf OpenReview finden. Gefährlicher wird die falsche Bilderkennung, wenn selbst fahrende Autos die Schilder nicht zuordnen können, weil sie möglicherweise verdreckt oder beklebt sind. Dass Objekte, die auf eine ungewöhnliche Weise dargestellt werden, auch oft nur fehlerhaft zugeordnet werden, wird z.B. bei Captchas genutzt.
|
Teachable Machine ist ein Online-Tool von Google, dass einen einfachen Einstieg in das Training von Neuronalen Nutzen liefert. Ein sehr ähnlich aufgebautes Programm von der Universität Ostfinnland gibt es auch: tm.gen-ai.fi
Mögliche weitere Objekte für die Bilderkennung:
|